movie actor ranking
Ranking of actor-behaviors based on movies dialogues from IMSDb and IMDb
Project Overview
The Movie Actor Ranking project was developed by Lukas Welker, Tony Meissner, and Patrik Lytschmann as part of an NLP & IR course.
The system enables users to find actors based on specific keywords or themes that appear in their movie roles, using advanced natural language processing and information retrieval techniques.
The project follows a comprehensive approach:
- Data Collection: Accessing IMDb datasets and IMSDb scripts for deeper analysis.
- Data Preprocessing: Cleaning the collected data, removing duplicates, and formatting movie scripts for analysis.
- Classification & IR Model: Using an emotion-modified BERT model to classify scripts and queries, and applying a Vector Space Model (VSM) for actor ranking.
- UI & API: Exposing functionality via FastAPI and a user-friendly interface built with Next.js and NextUI.
- Deployment & Evaluation: Containerizing with Docker, deploying to Azure, and evaluating the system using standard IR metrics like precision, recall, and F1-score.
Data Collection
Overview
The data collection process is a critical step in building an effective Information Retrieval (IR) system for identifying movie actors.
The main steps include:
- Scraping Movie Scripts from IMSDb
- Mapping IMDb to IMSDB Movie
- Splitting the Movie Script into Parts (Role + Dialogue)
- Mapping the Script Parts to the Actor
ER-model
The ER (Entity-Relationship) model for the movie-related database includes five main entities: ActorClassifier, Movie, Actor, Role, and Script.

Data collection steps
For the Data Collection we start with IMSDb (Internet Movie Script Database) because our model heavily relies on the movie scripts.
We used BeautifulSoup, a Python library for web scraping, to gather this data. The process involves:
1. Crawling IMSDB: We first crawl every possible movie information page on IMSDb by using the all scripts page. This resulted in a dataset of 1192 movies, each with a title, link, and script link.
| Title | Link | Script Link |
|---|---|---|
| 127 Hours | https://www.imsdb.com/Movie%20Scripts/127%20Hours%20Script.html | https://www.imsdb.com/scripts/127-Hours.html |
| Alien | https://www.imsdb.com/Movie%20Scripts/Alien%20Script.html | https://www.imsdb.com/scripts/Alien.html |
| … | … | … |
2. Crawling Movie Scripts: We then crawled the actual movie scripts from the script links obtained in the previous step.
This resulted in a dataset where each movie title is associated with its script.
| title | script |
|---|---|
| 127 Hours | ... |
| Alien | ... |
| … | … |
Mapping IMDb to IMSDB Movie
To enrich the movie scripts with additional information, we mapped the IMSDB movie data to IMDb (Internet Movie Database).
This involved:
1. Searching IMDb: For each movie title retrieved from IMSDB, we searched IMDb to retrieve additional information such as the cast and the movie cover.
2. Retrieving Cast Information: By mapping the movie script from IMSDB to IMDb, we were able to retrieve the cast information from IMDb, including actor names, roles, and headshots.
| imdb_movie_title | imdb_movie_id | imdb_movie_cover_url | imdb_actor_name | imdb_actor_id | role | imdb_actor_headshot_url |
|---|---|---|---|---|---|---|
| 127 Hours | 1542344 | … | James Franco | 0290556 | Aron Ralston | … |
| … | … | … | … | … | … | … |
Splitting the Movie Script into Parts (Role + Dialogue)
Extracting dialogues from movie scripts is a challenging task due to the unique formatting of each script.
We implemented a custom algorithm to handle this.
The algorithm filters out non-dialogue elements, focusing solely on the dialogues.
This was the most difficult part of data preparation because each script has its own unique terms and formatting.
When you look at the Figure 2, there is a cutout of the 127 Hours movie.

The algorithm only extracts this data, shown in the Table;
| movie | role | dialogueText |
|---|---|---|
| 127 Hours | ARON | Nearly missed it! |
| … | … | … |
Mapping the Script Parts to the Actor
After collecting and processing all the data, we mapped the script parts (roles and dialogues) to the corresponding actors.
This final step involved combining all the previously gathered information into a cohesive dataset.
| title | imdb_movie_id | actor | imdb_actor_id | role | dialogueText |
|---|---|---|---|---|---|
| 127 Hours | 1542344 | James Franco | 0290556 | Aron Ralston | Nearly missed it! |
| … | … | … | … | … | … |
By following these detailed steps, we ensured that our dataset was comprehensive and accurately represented the relationships between movie scripts, roles, and actors.
This structured approach to data collection is crucial for the subsequent stages of building and evaluating the IR system.
Classification Model
In this project, we utilize an emotion modified BERT-base-uncased language model; its name is zbnsl/bert-base-uncased-emotionsModified.
The BERT base model has been pretrained with BookCorpus, a dataset containing approximately 800 million words and with Wikipedia in English.
As already mentioned, the model we are using for this project is a modified version of the BERT language model.
The model we chose was furthermore trained with the go_emotions dataset.
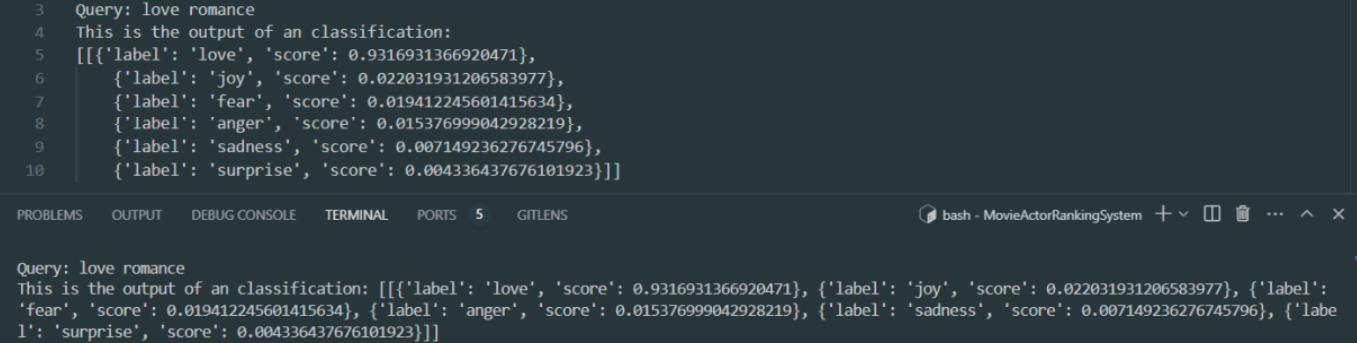
The model now takes any query as input and produces an output in the following format: List[List[Dict]].
The output consists of lists of dictionaries, where each list contains exactly six dictionaries.
Each dictionary represents one of the six emotional categories: love, joy, fear, anger, sadness, and surprise.
The following picture represents an example output for a query classification.
Implementation of IR System
Classification of scripts
To classify the different actors with the BERT classification model we need to classify the different scripts of the actors.
We implemented this by retrieving first all actors from the database and then getting all the roles for each actor.
Based on the role of an actor we can get the different scripts and classify each script with the classification model.
With all the different scripts classified in the six categories we can calculate an average value for each actor and therefore classify the calculated average classifications.
Figure 3 shows an example for the scripts of Ryan Gosling in the movie “Fracture”.
| Score Type | Script 1 | Script 2 | Script 3 |
|---|---|---|---|
| loveScore | 0.03 | 0.01 | 0.00 |
| joyScore | 0.41 | 0.97 | 0.98 |
| angerScore | 0.15 | 0.05 | 0.20 |
| sadnessScore | 0.35 | 0.01 | 0.00 |
| surpriseScore | 0.00 | 0.00 | 0.00 |
| fearScore | 0.05 | 0.01 | 0.01 |
With these values the calculated example vector would be 𝑉𝑎𝑐𝑡𝑜𝑟 =
We can now use this vector to create a vector space model.
Vector space model
In the context of Information Retrieval (IR), the Vector Space Model (VSM) represents each actor or query as a vector in Euclidean space, where each dimension corresponds to a unique classification category.
For the implementation in this project, we used the script as the basis, thus representing actors and queries as vectors of classification values.
In the context of a VSM actor or query vectors are denoted as 𝑥 = (𝑥1, …, 𝑥𝑘), where 𝑥𝑖 represents the real-valued classification value of the corresponding classification category.
Its crucial to note that these values are constrained to fall within the interval I = [0,1].
This constraint is significant as it ensures that each classification categorys value is normalized, meaning it ranges from complete absence (0) to absolute presence (1).
Now we have all prerequisites to carry out a ranking using the VSM and return the most representative movie actors based on a given query.
Both Queries and actors are vectors in the |K|-dimensional Euclidean space, where the classification categories represent the axes of the space.
We calculate the Cosine Similarity between each actor vector and query vector using the following formula:cosine_similarity (q,d) = 𝑞 ∗ 𝑑 / (|𝑞| ∗ |𝑑|), where 𝑞𝑖 is the classification value of category 𝑖 in the query and 𝑑𝑖 is the average classification value of category 𝑖 of the actor.
And we rank the documents according to their Cosine similarity.
For a random chosen query, we can observe cosine similarities between [0,99, 0,05].
Considering the range of our cosine similarities, we can conclude that the implemented Vector Space Model (VSM) is functioning correctly, if it produces a wide range of cosine similarities that are reflecting different degrees of relevance.
The cosine similarity values indicate that some actor vectors point in the same direction as the query vector, while others are orthogonal to it.
This implies that we have some actors who match the query quite well and others who do not match at all.
The main goal of this project is to identify representative movie actors by a given keyword.
This is realised by using our classification model to classify our script data and by classifying the user entered keyword.
While our implemented Vector Space Model (VSM) seems to be functioning correctly based on the range of cosine similarities observed,
we are facing still a significant interpretational issue.
If an actor has only played one role with a single line of text in an entire movie, and that line perfectly matches one of our classification categories,
the cosine similarity between this actors vector and a query matching the same category is going to be very high.
This means that, although the certain actor has minimal participation, the VSM might inaccurately indicate a high relevance to the query.
As a result, the model could suggest that such an actor is highly relevant to the classification category, despite their limited contribution.
This leads to misleading interpretations, where actors with many and versatile roles might appear less relevant compared to those with minimal but better aligned contributions in a specific classification category.
In order to avoid this interpretational issue, we must extend our understanding of the underlying user needs.
We need to add another goal to our main objective for the IR system: considering the overall involvement of an actor.
This means we need to value not only the number of movies an actor participates in but also how many parts of the script are associated with that specific actor.
To integrate our newly identified sub goal in the IR system, we multiply our before computed cosine similarity by a real valued coefficient 𝑘,
which is proportional to the number of associated scripts to an actor.
We stored these by a coefficient weighted cosine similarities in a python dictionary.
Finally, we can sort the created dictionary by descending order using the Python built-in sorted()-function with a time complexity of O(nlogn)
and return a List of k documents to the user.
Exposing the Functions
FastAPI
We implemented a FastAPI endpoint for both our search_vector_space function.
This endpoint creates the opportunity for external applications or user interfaces to interact with our implemented IR system programmatically via HTTP requests.
On the following picture you can see the implemented API endpoint.
If a user is interacting with our IR system by entering a query, this specific query gets processed by our IR system.
In the same manner it is possible to interact with our system by using an UI.
Search Classifier Actor
Search Token Actor
User Interface
Complementing the API access, we built a web interface with Next.js and NextUI to offer a more interactive search experience.
Users can directly interact with the IR system through their web browser.
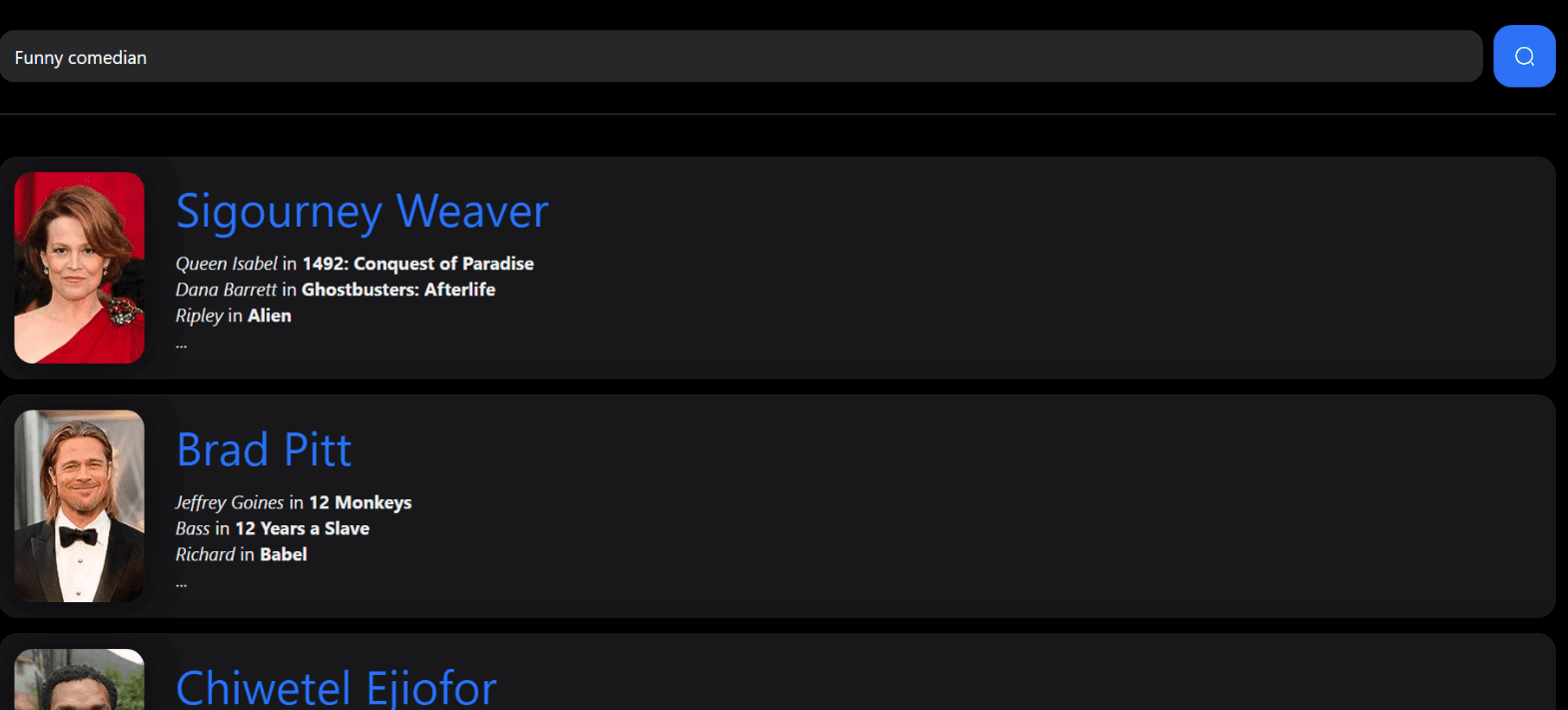
On the following picture you can see the search process with the VSM, using an custom query.
Deployment
The entire application, including search functionalities and the web interface, is deployed via a Docker image on Microsoft Azure App Service to make it available to everyone.
Access the web interface here: https://app-movieactorranking-prod.azurewebsites.net/
Access the web API here: https://api-movieactorranking-prod.azurewebsites.net/docs
Evaluation
We chose precision, recall, and F1-score to evaluate our information retrieval model.
These metrics effectively assess model performance by balancing relevance (recall) and retrieved document proportion (precision), aligning with standard evaluation practices.
Furthermore, these metrics are robust for imbalanced datasets common in information retrieval, unlike metrics focused solely on retrieved documents.
They consider both retrieved and non-retrieved actors, providing a more accurate picture.
The evaluation function takes the search function, arguments, query/document dataframes, and pre-annotated relevance information.
It iterates through queries and retrieves relevant actors (ground truth) and those retrieved by the model.
As you can see in the following Table, we used 6 queries to evaluate our models.
| Number | Query |
|---|---|
| 1 | romantic scenes |
| 2 | action filled dramas |
| 3 | funniest actors ever |
| 4 | heartbreaking roles |
| 5 | saddest movie performances |
| 6 | action-packed movie stars |
Then, with only lists on IMDB and other sources we created a top 20 actor list for each query.
| rank | romantic scenes | action filled dramas | funniest actors ever | heartbreaking roles | saddest movie performances | action-packed movie stars |
|---|---|---|---|---|---|---|
| 1 | Ryan Gosling | Denzel Washington | Jim Carrey | Tom Hanks | Tom Hanks | Arnold Schwarzenegger |
| 2 | Julia Roberts | Tom Cruise | Will Ferrell | Meryl Streep | Anne Hathaway | Sylvester Stallone |
| 3 | Hugh Grant | Keanu Reeves | Bill Murray | Leonardo DiCaprio | Leonardo DiCaprio | Bruce Lee |
| … | … | … | … | … | … | … |
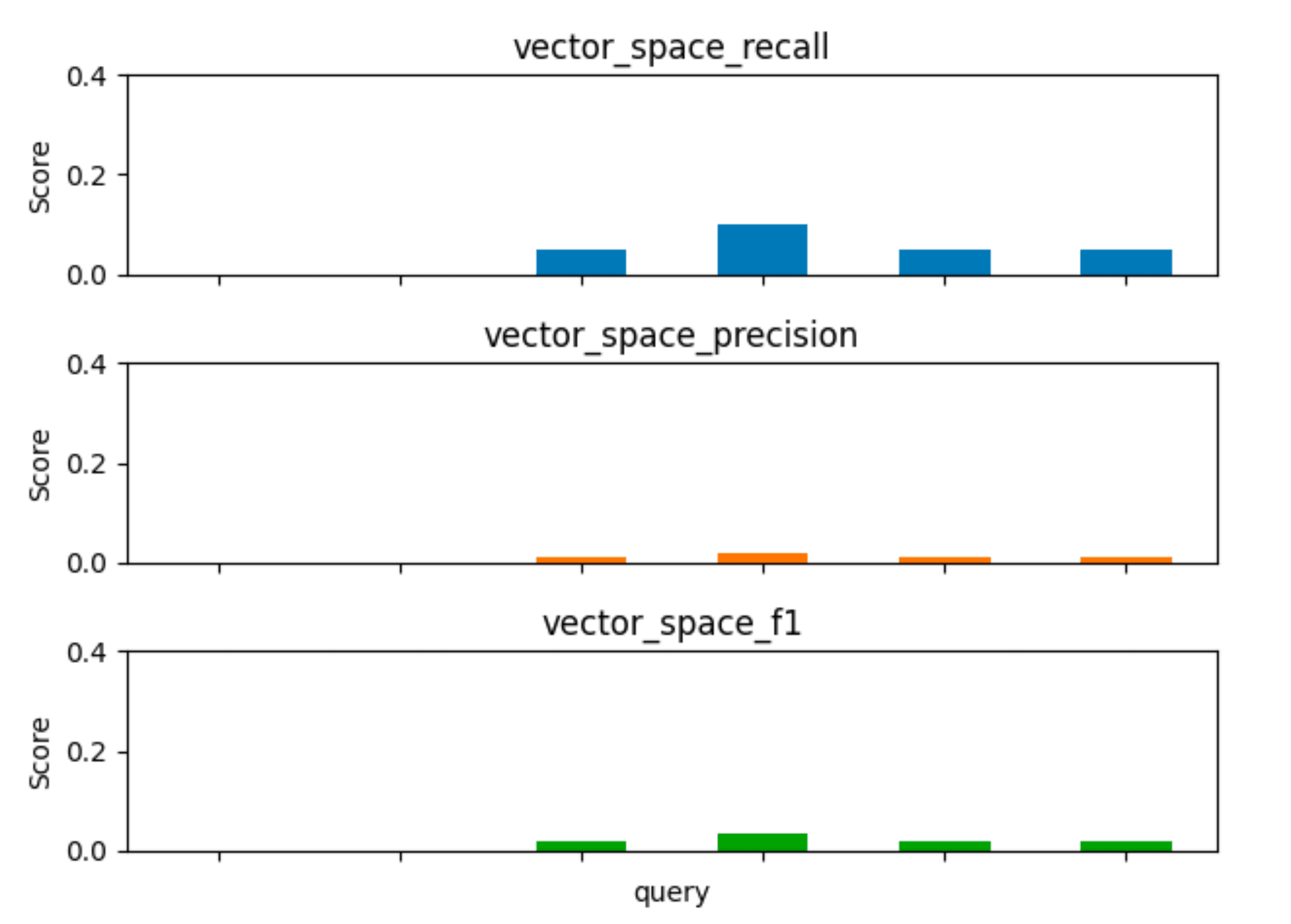
In Figure 4 you can see the evaluation of the recall, precision and f1 values for each query.
With a fame coefficient weight of 15%.
That means we calculate the final score with: score_actor = similarity_actor ⋅ 85% + fame_actor ⋅ 15%
As you can see in the Table, we also calculated total numbers of all the results.
| Recall | Precision | F1 | |
|---|---|---|---|
| Mean | 0.0416 | 0.0083 | 0.0139 |
| Min | 0.0000 | 0.0000 | 0.0000 |
| Max: | 0.1000 | 0.0200 | 0.0333 |
When it comes to recall, the model has a minimum value of 0 and maximum of 0,1.
With a minimum score of 0 and a maximum score of 0,02 in the precision column.
A higher F1 score indicates a better overall performance of the IR system, as it considers both the retrieved documents relevance and the completeness of the retrieval.
Looking at the F1 score of the model, you can see a minimum value of 0 and maximum of 0,03.
Overall, our results are not good, but this is because our collected data is missing a lot of important scripts.
For example, the actor Henry Cavill has not a single dialog in our database and is missing completely in the results because of that.
Also, we could have trained the AI model with our movie script data if we had more time for the project which would also result in better results.
In general, we also think that six categories and therefore six dimensions in the vector space model are too little for our case.
So overall we assume that the evaluation scores are so poor because we have too little data and the AI model used for the classification is not optimal.
In a bigger future project, we would include even more ranking factors instead of only the cosine similarity and the fame coefficient to create an even more specific ranking of the actors.
Also, we could then use an evolutionary AI model to set initial values for the weight of the different factors and then change some values and test if the F1-score improved or not.